About me
I am a third year Ph.D. student in the Allen School of Computer Science and Engineering at the University of Washington, advised by Yulia Tsvetkov. I do research in Natural Language Processing and Cognitive Modeling, with a growing emphasis on personalization and proactive learning (question-asking).
I'm particularly interested in using computational methods to model cognitive processes, including how humans reason, communicate uncertainty, and make decisions in complex domains like healthcare. My long-term goal is to build socially and cognitively aligned AI systems that support safer, more personalized, and equitable care.
Research interests: AI for Health, Safety & Reliability, Proactive Learning, Social Reasoning, and more!
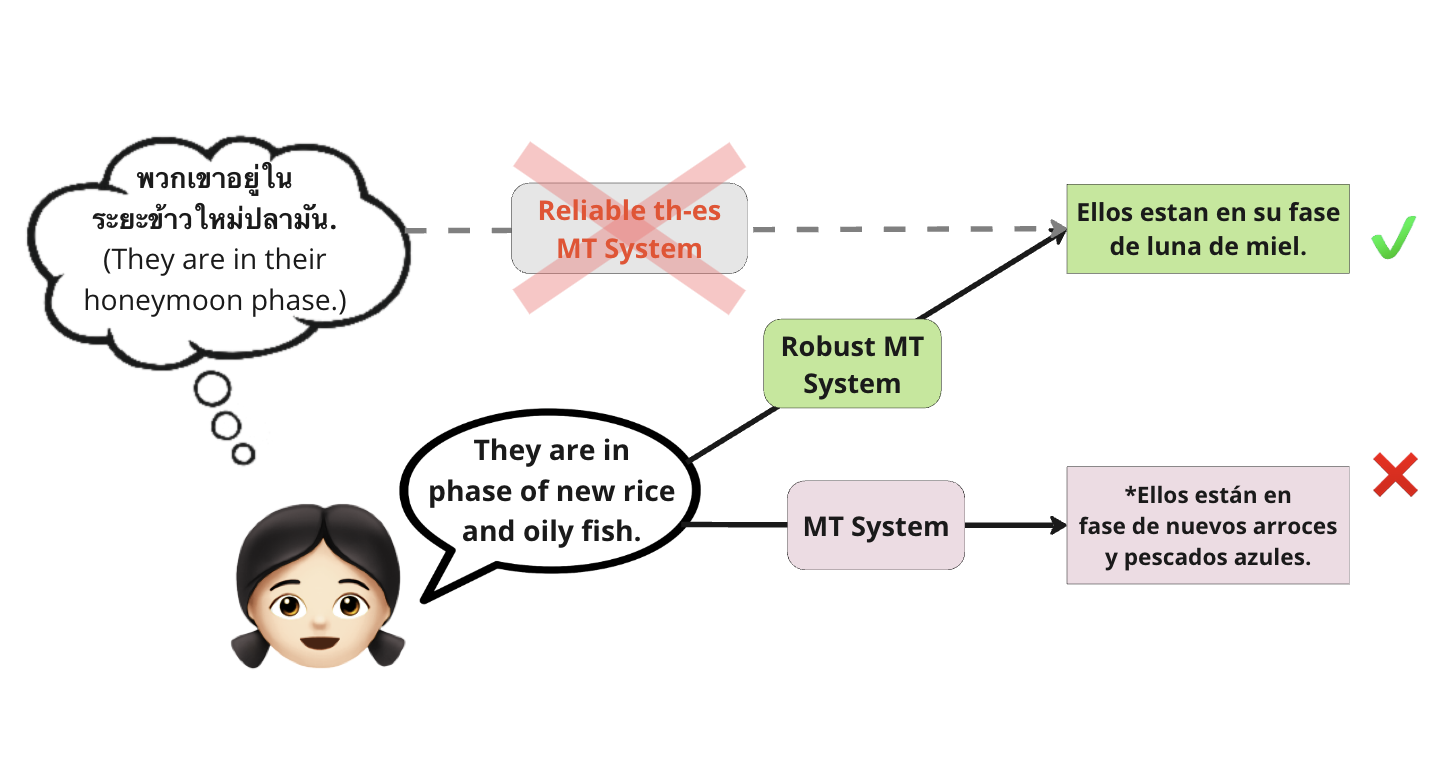
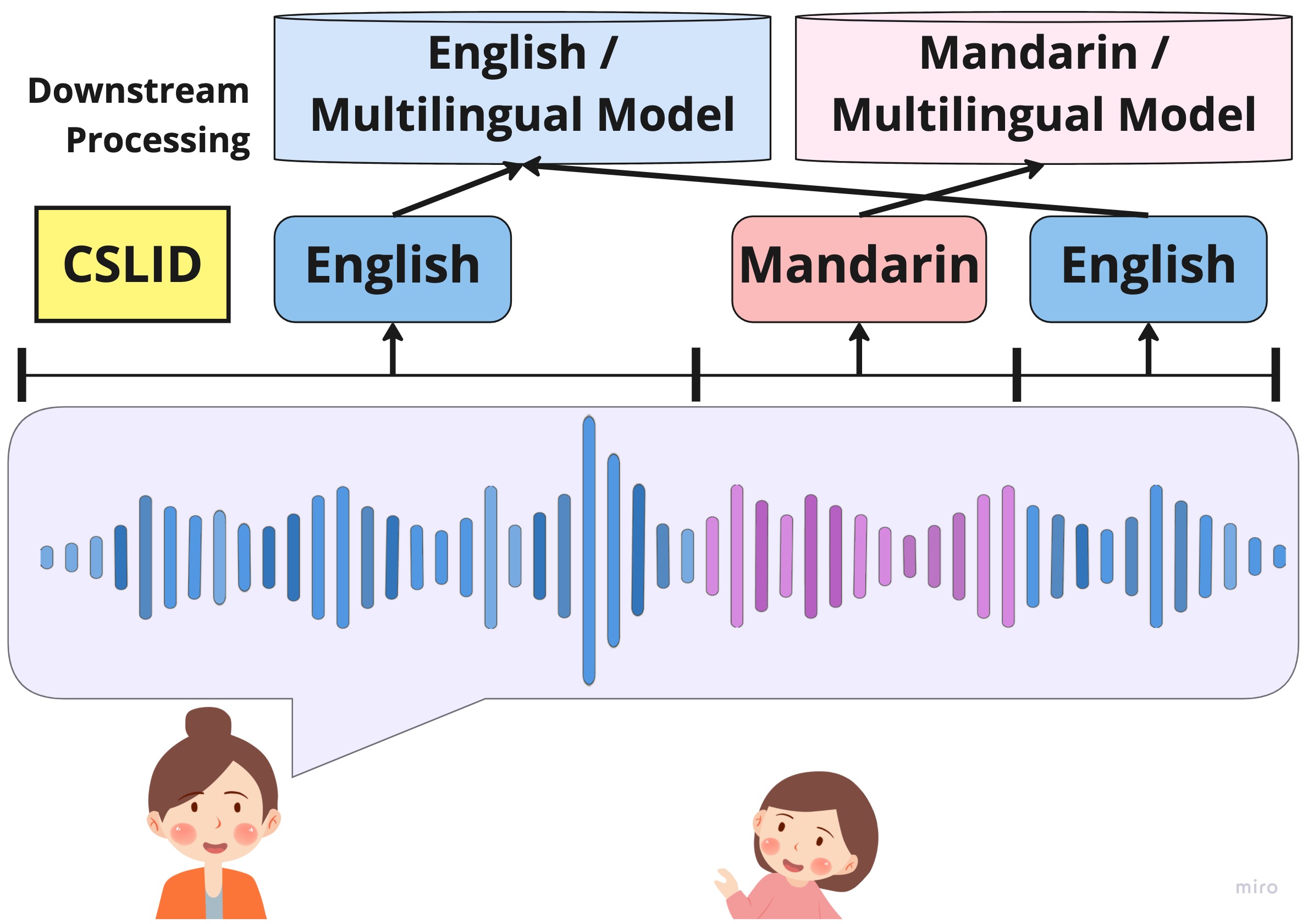
Before grad school, I received my B.S. and M.S.E. at Johns Hopkins with majors in Computer Science, Cognitive Science (linguistics focus), and Applied Mathematics (statistics focus). I worked as a research assistant at the Center for Language and Speech Processing advised by Philipp Koehn and Kenton Murray.
Please contact me at stelli [at] cs.washington.edu if you are interested in my work!
Click here to view my CV (updated July 25)
Current Projects
-

Proactive Reasoning
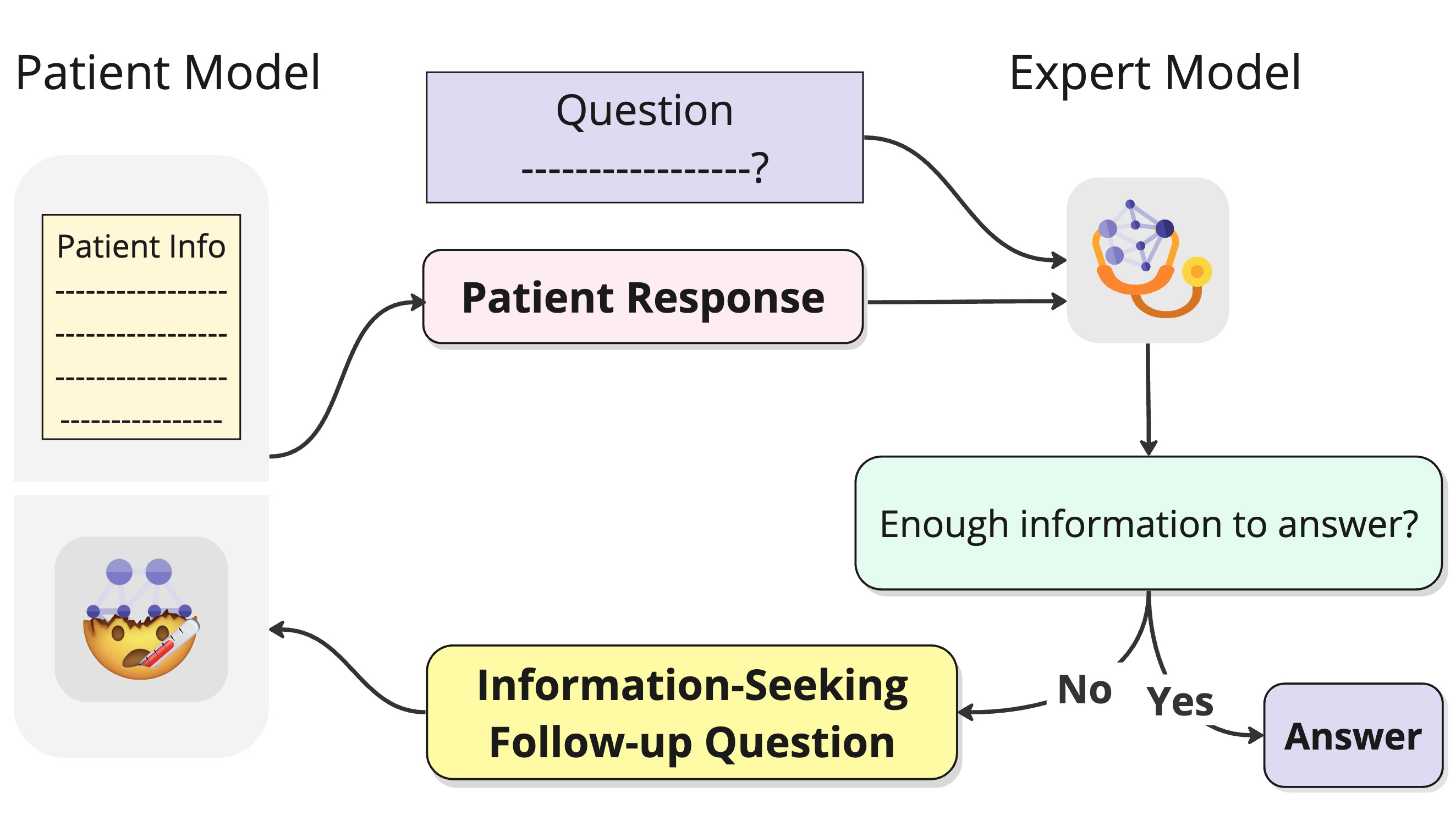
I'm thinking about how to identify and proactively seek information using LLMs to improve model safety & reliability with statistical guarantee. How to make LLMs ask good questions? How do we model "intuition" in expert domains like medicine?
-

Socially-Intelligent Personalization
Modeling how different social groups express health concerns and interpret medical advice. Aiming to personalize AI systems for more equitable, culturally-aware health communication.
News
-
2026-01
Our paper "Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It" got accepted to ICLR 2026🇧🇷!
-
2025-11
Check out our new paper "Cognitive Foundations for Reasoning and Their Manifestation in LLMs" that extracts and analyze patterns in LLM and human reasoning.
-
2025-11
Guest lecture at UT Austin Computational Discourse and NLG class on PrefPalette [Slides].
-
2025-08
"PrefPalette: Personalized Preference Modeling with Latent Attributes" won a Spotlight at COLM 2025🏆!
-
2025-06
Presenting Spurious Rewards at Cohere Labs [YouTube] [Slides].
-
2025-06
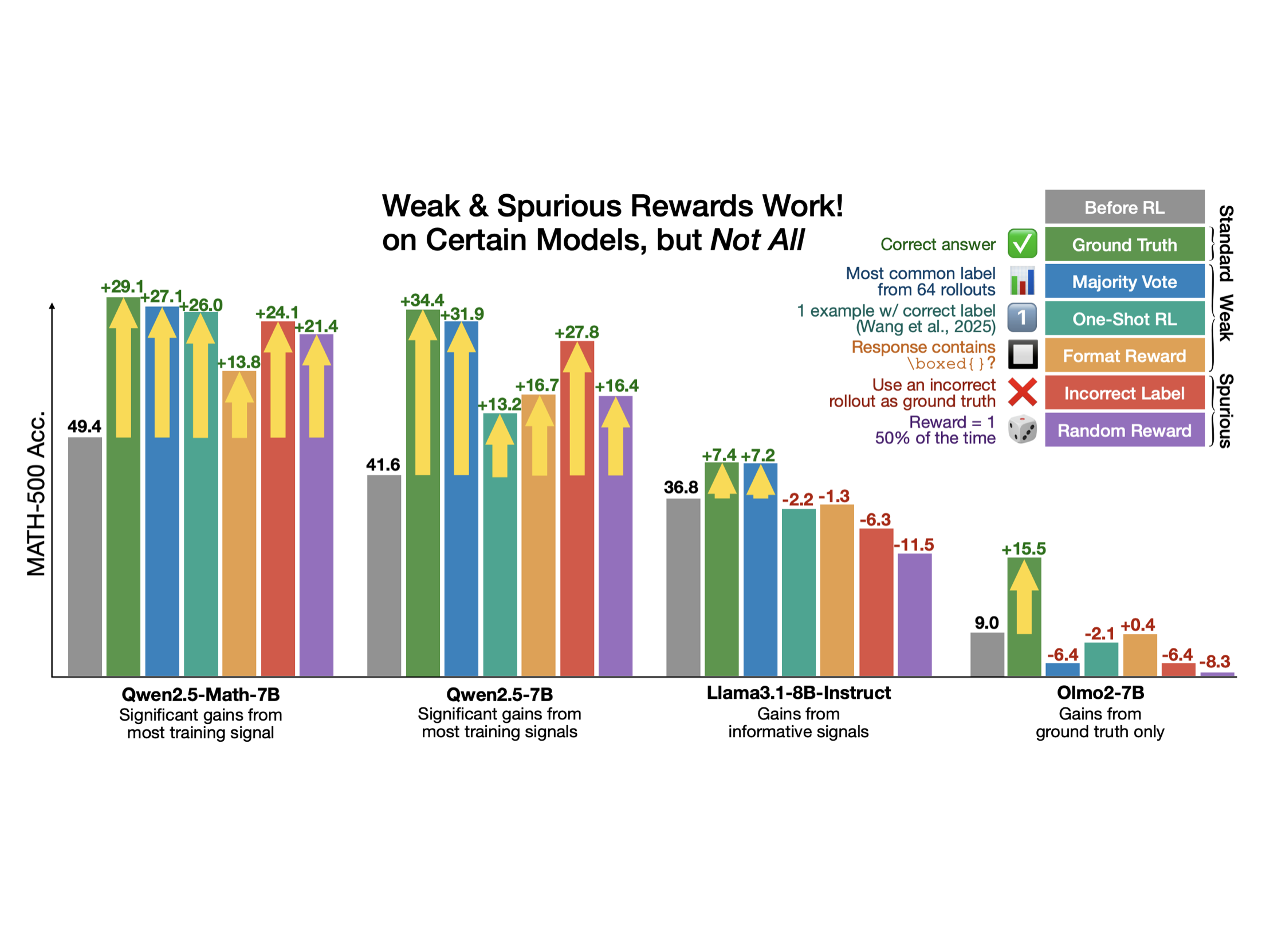
Prompt engineering can elicit similar behaviors in models as RLVR does. We show that "Spurious Prompt" can boost Qwen2.5-Math MATH-500 performance by 20% as well‼️ Check out our new blogpost "Spurious Rewards and Spurious Prompts."
-
2025-05
Doing RLVR on incorrect and even random rewards can boost Qwen2.5-Math MATH-500 performance by 20%🤯 We explore how and why this happens in our new paper "Spurious Rewards: Rethinking Training Signals in RLVR" (blogpost).